Searching for information on an internal website is often not straightforward. You can't rely on a public search engine to find that content, so you need to provide your own solution. You can't rebuild Google or Bing, but you can still build something good enough. In this series, I'll show you how to quickly create a search engine for your internal websites using Playwright and Elasticsearch.
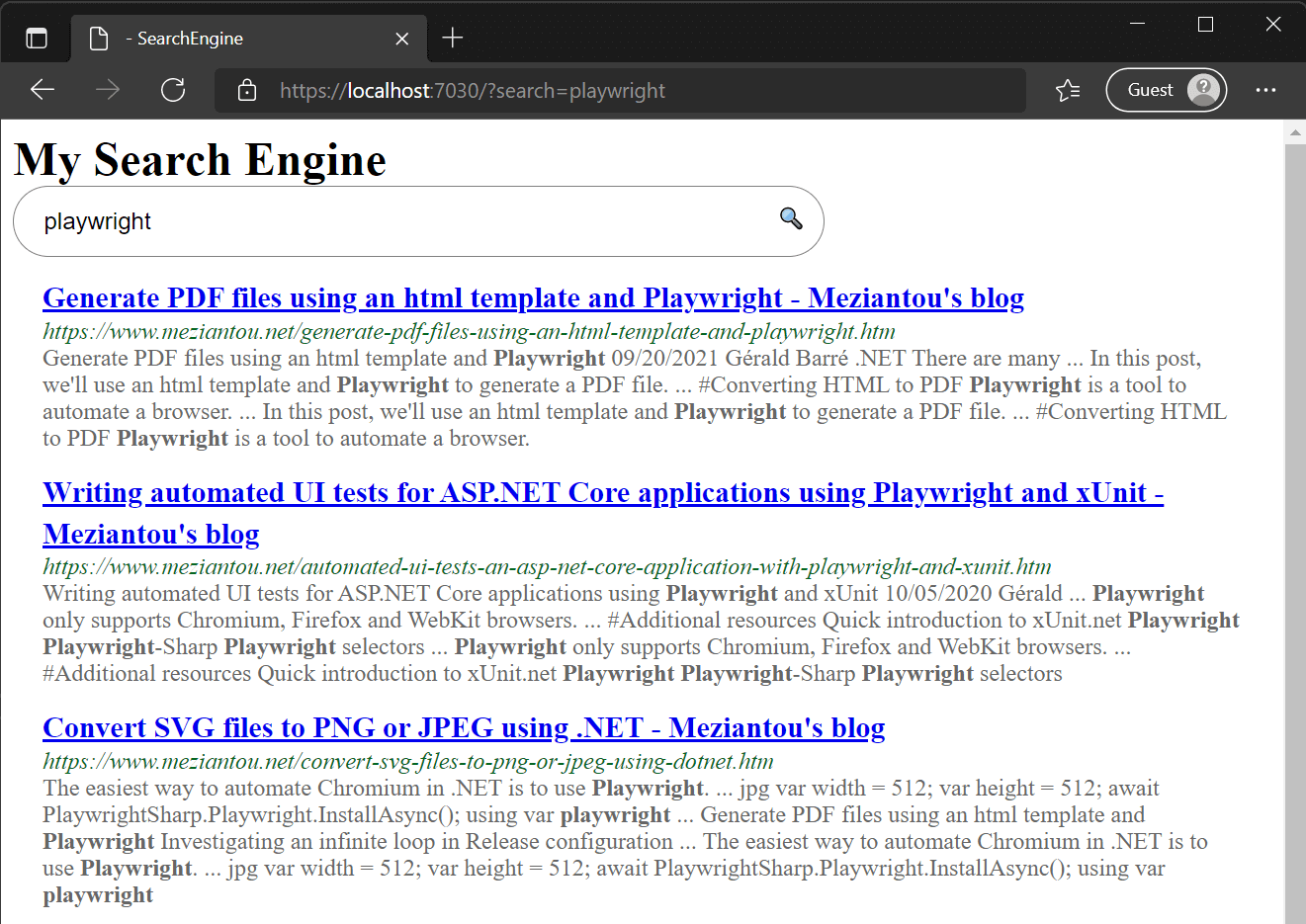
A search engine allows users to search for content and surfaces relevant results. This requires finding and indexing all pages. Finding pages is straightforward; indexing the content is the harder part. You don't need to match the sophistication of major search engines. A simple approach is to use Elasticsearch to index the text content of pages. This lets you search for words across pages, and Elasticsearch returns results sorted by relevance.
To index pages, you need to crawl websites and extract their content. Some pages use JavaScript to load dynamic content, so you need a real browser to render them correctly before indexing. This is where Playwright comes in. Playwright provides an API to automate Chromium, Firefox, and WebKit. You can open a page, extract its text and links to other pages, then follow those links and repeat until you have visited all pages.
#Indexing pages
This project crawls a website and stores its content in Elasticsearch. The first step is to have an Elasticsearch instance running. If you don't have one, you can use Docker to start one quickly:
PowerShell
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.15.0
Then, create a new console project and add references to Playwright and NEST (the Elasticsearch client). For Playwright, you also need to use the CLI to install the browsers.
Shell
dotnet new console
dotnet add package Microsoft.Playwright
dotnet add package NEST
dotnet tool update --global Microsoft.Playwright.CLI
dotnet build
playwright install
Then, use the following code:
C#
using Microsoft.Playwright;
var rootUrl = new Uri("https://example.com");
var urlsToProcess = new Queue<Uri>();
urlsToProcess.Enqueue(rootUrl);
// Keep a list of all visited urls,
// so we don't process the same url twice
var visitedUrls = new HashSet<Uri>();
// Initialize Elasticsearch
var elasticClient = new Nest.ElasticClient(new Uri("http://localhost:9200"));
var indexName = "example-pages";
await elasticClient.Indices.CreateAsync(indexName);
// Initialize Playwright
using var playwright = await Playwright.CreateAsync();
await using var browser = await playwright.Chromium.LaunchAsync();
await using var browserContext = await browser.NewContextAsync();
var page = await browserContext.NewPageAsync();
// Process urls
while (urlsToProcess.TryDequeue(out var uri))
{
if (!visitedUrls.Add(uri))
continue;
Console.WriteLine($"Indexing {uri}");
// Open the page
var pageGotoOptions = new PageGotoOptions { WaitUntil = WaitUntilState.NetworkIdle };
var response = await page.GotoAsync(uri.AbsoluteUri, pageGotoOptions);
if (response == null || !response.Ok)
{
Console.WriteLine($"Cannot open the page {uri}");
continue;
}
// Extract data from the page
var elasticPage = new ElasticWebPage
{
Url = (await GetCanonicalUrl(page)).AbsoluteUri,
Contents = await GetMainContents(page),
Title = await page.TitleAsync(),
};
// Store the data in Elasticsearch
await elasticClient.IndexAsync(elasticPage, i => i.Index(indexName));
// Find all links and add them to the queue
// note: we do not want to explorer all the web,
// so we filter out url that are not from the rootUrl's domain
var links = await GetLinks(page);
foreach (var link in links)
{
if (!visitedUrls.Add(link) && link.Host == rootUrl.Host)
urlsToProcess.Enqueue(link);
}
}
// Search for <link rel=canonical href="value"> to only index similar pages once
async Task<Uri> GetCanonicalUrl(IPage page)
{
var pageUrl = new Uri(page.Url, UriKind.Absolute);
var link = await page.QuerySelectorAsync("link[rel=canonical]");
if (link != null)
{
var href = await link.GetAttributeAsync("href");
if (Uri.TryCreate(pageUrl, href, out var result))
return result;
}
return pageUrl;
}
// Extract all <a href="value"> from the page
async Task<IReadOnlyCollection<Uri>> GetLinks(IPage page)
{
var result = new List<Uri>();
var anchors = await page.QuerySelectorAllAsync("a[href]");
foreach (var anchor in anchors)
{
var href = await anchor.EvaluateAsync<string>("node => node.href");
if (!Uri.TryCreate(href, UriKind.Absolute, out var url))
continue;
result.Add(url);
}
return result;
}
// The logic is to search for the <main> elements or any element
// with the attribute role="main"
// Also, we use the non-standard "innerText" property as it considers
// the style to remove invisible text.
async Task<IReadOnlyCollection<string>> GetMainContents(IPage page)
{
var result = new List<string>();
var elements = await page.QuerySelectorAllAsync("main, *[role=main]");
if (elements.Any())
{
foreach (var element in elements)
{
var innerText = await element.EvaluateAsync<string>("node => node.innerText");
result.Add(innerText);
}
}
else
{
var innerText = await page.InnerTextAsync("body");
result.Add(innerText);
}
return result;
}
[Nest.ElasticsearchType(IdProperty = nameof(Url))]
public sealed class ElasticWebPage
{
[Nest.Keyword]
public string? Url { get; set; }
[Nest.Text]
public string? Title { get; set; }
[Nest.Text]
public IEnumerable<string>? Contents { get; set; }
}
Run the code with dotnet run. It will crawl the website and index all pages.
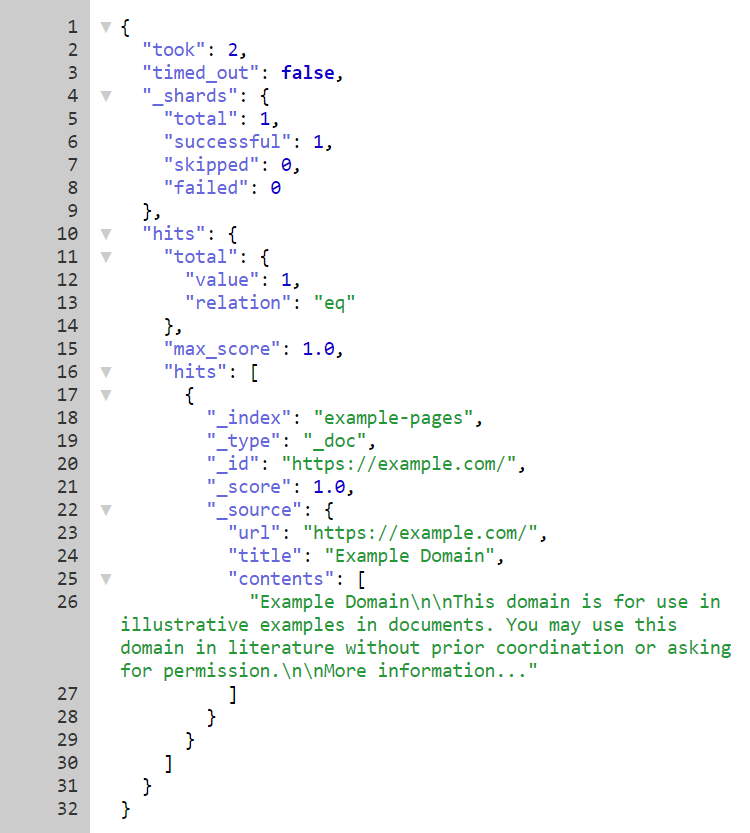
You can verify the indexed content using Kibana or by navigating to http://localhost:9200/example-pages/_search. The latter should display a few documents from the index:
#Searching data in Elasticsearch
This project is a web application that queries the Elasticsearch index to display results.
The first step is to create a new web application and add a reference to NEST (the Elasticsearch client):
PowerShell
dotnet new razor
dotnet add package NEST
Then, replace the content of index.razor with the following:
Razor
@page
@using Microsoft.AspNetCore.Html
@using Nest
<h1>My Search Engine</h1>
<form method="get">
<div class="searchbox">
<input type="search" name="search" placeholder="query..." value="@Search" />
<button type="submit">🔍</button>
</div>
</form>
<ol class="results">
@foreach (var match in matches)
{
<li class="result">
<h2 class="result_title"><a href="@match.Url" target="_blank">@match.Title</a></h2>
<div class="result_attribution">
<cite>@match.Url</cite>
</div>
<p>@match.Highlight</p>
</li>
}
</ol>
@functions {
private List<MatchResult> matches = new();
[FromQuery(Name = "search")]
public string? Search { get; set; }
public async Task OnGet()
{
if (Search == null)
return;
var settings = new ConnectionSettings(new Uri("http://localhost:9200"))
.DefaultIndex("example-pages");
var client = new ElasticClient(settings);
var result = await client.SearchAsync<ElasticWebPage>(s => s
.Query(q => q
.Bool(b =>
b.Should(
bs => bs.Match(m => m.Field(f => f.Contents).Query(Search)),
bs => bs.Match(m => m.Field(f => f.Title).Query(Search))
)
)
)
.Highlight(h => h
.Fields(f => f
.Field(f => f.Contents)
.PreTags("<strong>")
.PostTags("</strong>")))
);
var hits = result.Hits
.OrderByDescending(hit => hit.Score)
.DistinctBy(hit => hit.Source.Url);
foreach (var hit in hits)
{
// Merge highlights and add the match to the result list
var highlight = string.Join("...", hit.Highlight.SelectMany(h => h.Value));
matches.Add(new(hit.Source.Title!, hit.Source.Url!, new HtmlString(highlight)));
}
}
record MatchResult(string Title, string Url, HtmlString Highlight);
[Nest.ElasticsearchType(IdProperty = nameof(Url))]
public sealed class ElasticWebPage
{
public string? Url { get; set; }
public string? Title { get; set; }
public IEnumerable<string>? Contents { get; set; }
}
}
You can improve the UI with a few CSS rules:
CSS
h1, h2, h3, h4, h5, h6, p, ol, ul, li {
border: 0;
border-collapse: collapse;
border-spacing: 0;
list-style: none;
margin: 0;
padding: 0;
}
.searchbox {
width: 545px;
border: gray 1px solid;
border-radius: 24px;
}
.searchbox button {
margin: 0;
transform: none;
background-image: none;
background-color: transparent;
width: 40px;
height: 40px;
border-radius: 50%;
border: none;
cursor: pointer;
}
input {
width: 499px;
font-size: 16px;
margin: 1px 0 1px 1px;
padding: 0 10px 0 19px;
border: 0;
max-height: none;
outline: none;
box-sizing: border-box;
height: 44px;
vertical-align: top;
border-radius: 6px;
background-color: transparent;
}
.results {
color: #666;
}
.result {
padding: 12px 20px 0;
}
.result_title > a {
font-size: 20px;
line-height: 24px;
font: 'Roboto',Sans-Serif;
}
.result_attribution {
padding: 1px 0 0 0;
}
.result_attribution > cite {
color: #006621;
}
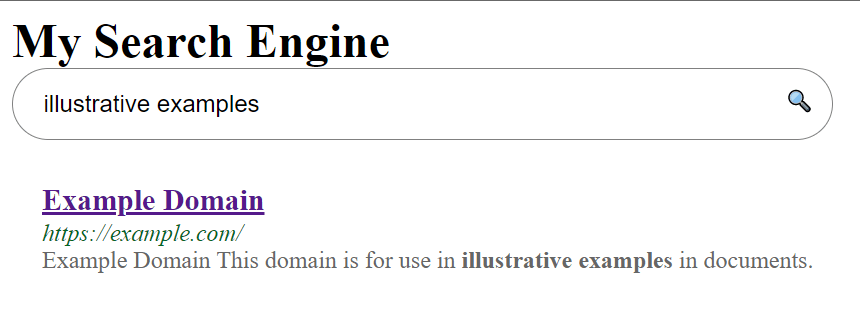
Run the web application with dotnet run and try your first query:
#Conclusion
In a few dozen lines of code, you can build a search engine for your websites using Playwright and Elasticsearch. It is not a Google replacement, but the results can be good enough for your needs. You can also extract more data such as page descriptions, links, or headers, and weight each field to improve result ranking. Another improvement is to use sitemaps and feeds to crawl websites, ensuring you don't miss any important pages.
Notes:
- If the websites you want to index don't use JavaScript or advanced browser features, you can replace Playwright with AngleSharp, which is faster.
- The sample on GitHub is faster because it indexes pages in parallel and extracts more data.
#Additional resources
Do you have a question or a suggestion about this post? Contact me!