With the advent of ORMs such as Entity Framework, developers often forget the issues related to database developments. Indeed, ORMs and similar tools often deal with generating the schema (tables, columns) of the database as well as generating SQL queries without the developer writing a single line of SQL. Although this is very practical, a database is not limited to just that. There are stored procedures, CLR functions, Queues (Service Broker), configuration (compatibility level, collation, snapshot isolation, etc.), and many other things.
All these objects change as the application evolves. It is therefore important, just like for application code, to version the code of the database. Also, you must be able to easily deploy a new database or update an existing database to the latest version of the schema. In this post, we will see how the SQL Server Database Project can solve this problem.
#Integrated with Visual Studio
This project is integrated with Visual Studio. This has many advantages:
- All the code of the application is in the same place (C# + SQL + others)
- You can take advantage of all the features of source control (TFS or Git)
- The project is integrated into the build process including for automatic builds (continuous integration / Continuous delivery)
- This is a familiar environment for many people
#Importing a database or SQL script
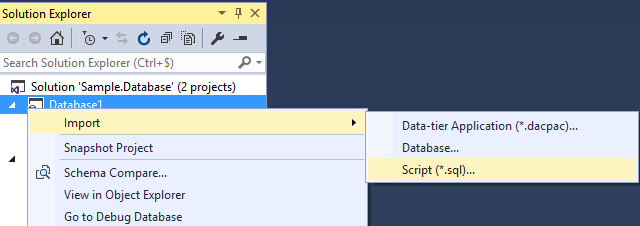
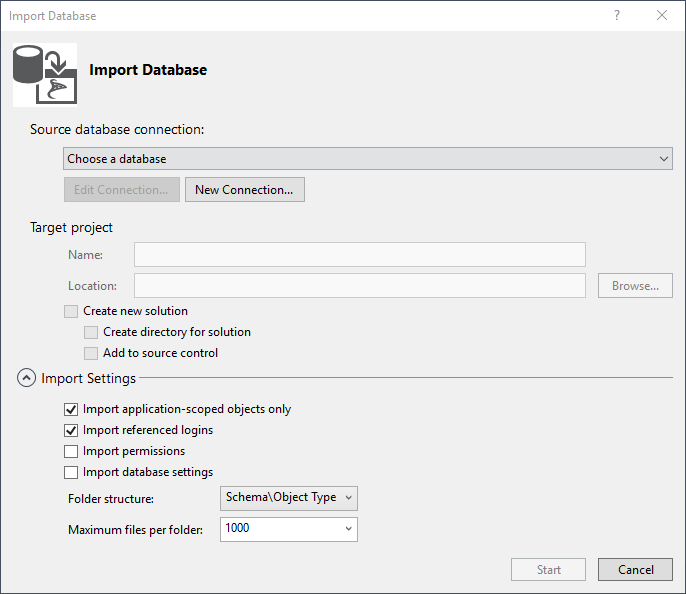
It is possible to initiate the project from a database. So even if you do not use this kind of project to create your database, you can start enjoying all the features it offers in seconds. Similarly, if you already have a script containing SQL statements for creating objects, it will be parsed and each CREATE statement will be retrieved and placed in a separate script.
You can choose the target version of SQL Server (including Azure). This makes it possible to modify the behavior of auto-completion and validation of errors. If you select SQL Server 2005, the new features (Table In-Memory, Sequences, etc.) will not be allowed. You make sure that the code you write will work on the targeted version.
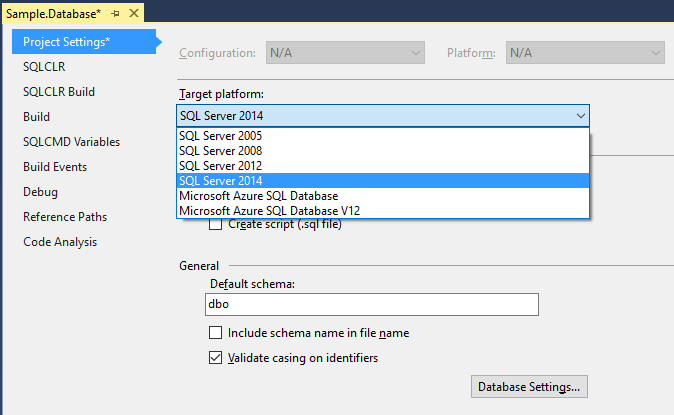
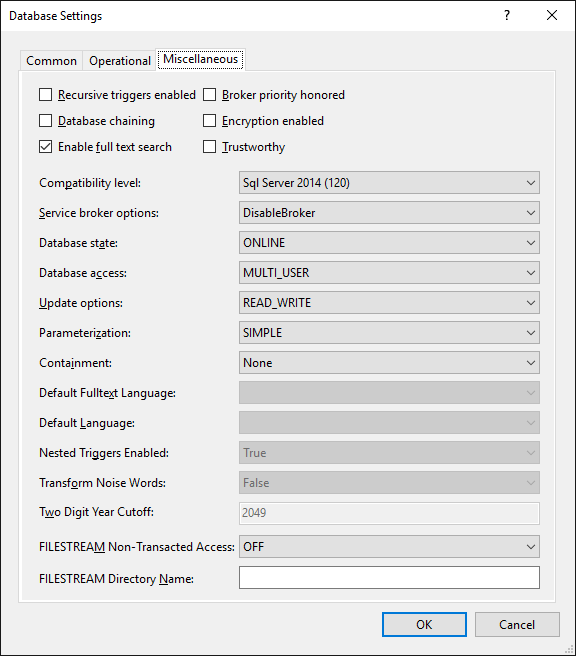
You can also change the settings of the database. This ensures that all the parameters will be identical regardless of the server on which the database will be deployed:
#Declarative model
The database is described in a declarative way. This means that you describe how the base should be, not how to get that state. This translates into the fact that all objects are saved with CREATE statements, there is no DROP IF EXISTS ... or ALTER .... It is up to the deployment process to choose how to obtain this state (remember the article on dacpac).
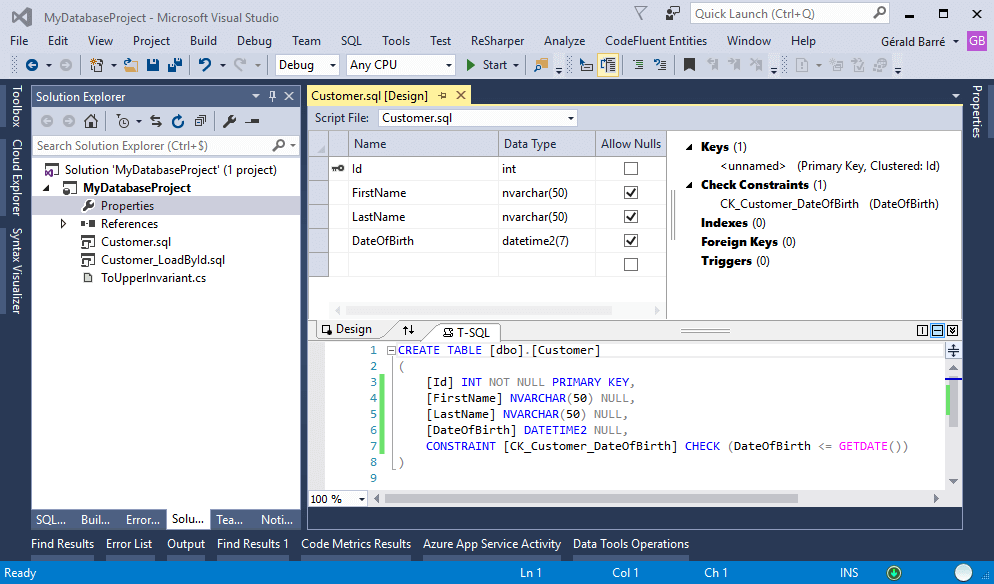
This project can contain SQL scripts as well as C# code. The editors are complete and offer syntax highlighting as well as autocompletion, whether for SQL scripts or .NET code:
#Smart Refactoring
Just like for a C# project, Visual Studio offers several refactoring:
- Change the name of an object
- Change the schema of an object
- Replace
SELECT * with the list of all columns - Replace the object names with full names if possible (schema.table.column)
These refactoring can be very practical especially if the database contains many objects:
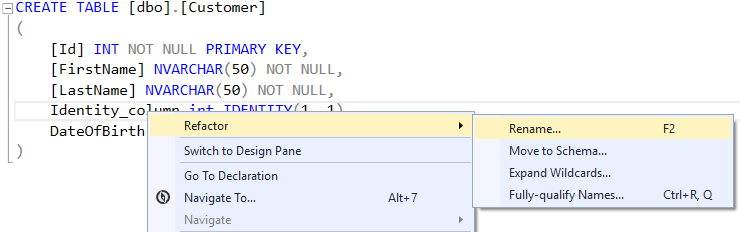
Why smart? When you rename an object, a .refactorlog file is created. This file is used to modify the standard behavior when generating the database deployment script. Instead of dropping a column and creating a new one, the script will rename the existing column in the database if it has been declared as rename in the .refactorlog file.
XML
<?xml version="1.0" encoding="utf-8"?>
<Operations Version="1.0" xmlns="http://schemas.microsoft.com/sqlserver/dac/Serialization/2012/02">
<Operation Name="Rename Refactor" Key="2b862e7a-7b19-4cfb-af61-32fa43235070" ChangeDateTime="12/14/2015 20:32:16">
<Property Name="ElementName" Value="[dbo].[Customer].[Identity_column]" />
<Property Name="ElementType" Value="SqlSimpleColumn" />
<Property Name="ParentElementName" Value="[dbo].[Customer]" />
<Property Name="ParentElementType" Value="SqlTable" />
<Property Name="NewName" Value="Identity_columnRenamed" />
</Operation>
</Operations>
SQL
-- Excerpt from the generated update script
PRINT N'The following operation was generated from a refactoring log file 2b862e7a-7b19-4cfb-af61-32fa43235070';
PRINT N'Rename [dbo].[Customer].[Identity_column] to Identity_columnRenamed';
GO
EXECUTE sp_rename @objname = N'[dbo].[Customer].[Identity_column]', @newname = N'Identity_columnRenamed', @objtype = N'COLUMN';
GO
-- Refactoring step to update target server with deployed transaction logs
IF NOT EXISTS (SELECT OperationKey FROM [dbo].[__RefactorLog] WHERE OperationKey = '2b862e7a-7b19-4cfb-af61-32fa43235070')
INSERT INTO [dbo].[__RefactorLog] (OperationKey) values ('2b862e7a-7b19-4cfb-af61-32fa43235070')
GO
#Error detection
The project is compiled. This makes it possible to identify a maximum number of errors immediately without having to execute each of the procedures manually on the server:
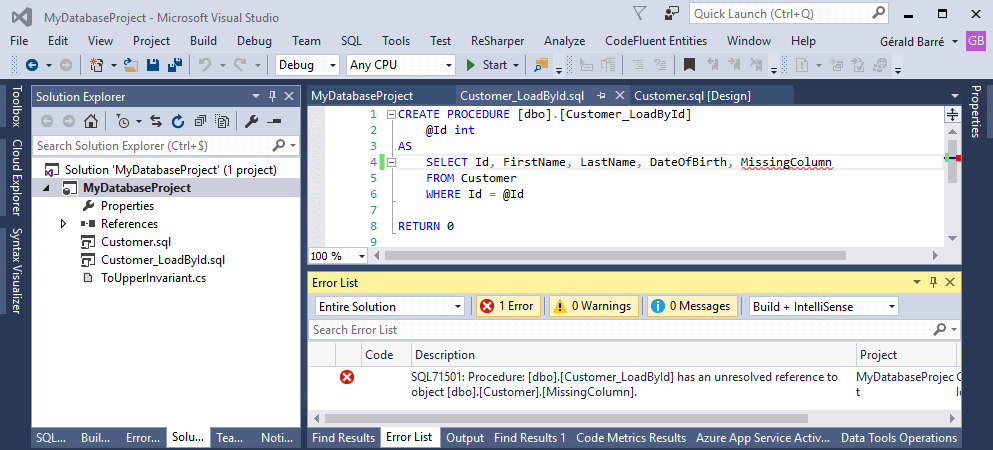
However, SQL Server can do a lot of things, some of which cannot be statically verified. Some errors will be visible only at runtime, but at least the stupid ones will be avoided!
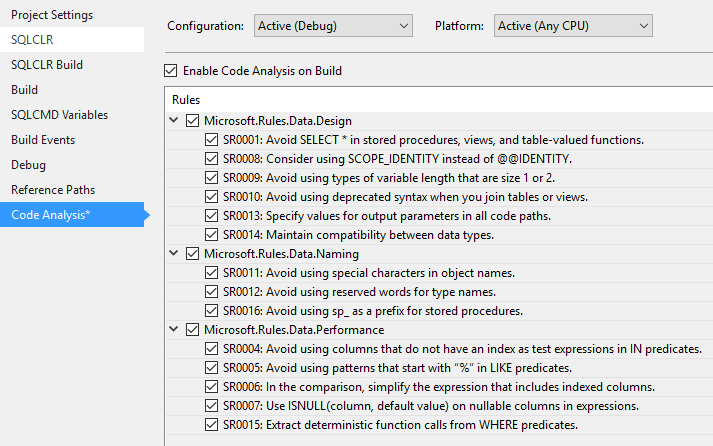
#Code analysis
Like .NET projects, Visual Studio can verify that the code does not violate the conventions defined for the project:

#Compilation & Deployment
The result of the compilation is a dacpac file allowing the deployment of the database. Thanks to this unique file, it is possible to create a blank database or to update an already existing database. For this, you can use Visual Studio (right-click / Publish), SQL Server Management Studio, or SqlPackage.exe. I've already written a post on publishing dacpac files, I invite you to read it for more details.
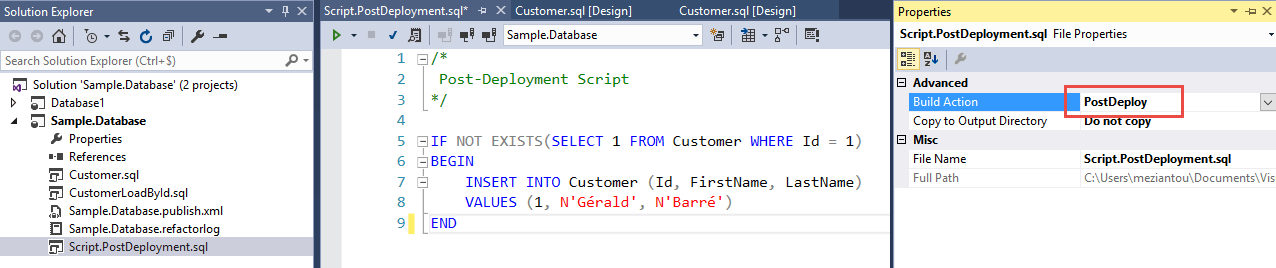
#Scripts pre/post-deployment
The deployment process is not very customizable since it is fully managed by the standard dacpac mechanism. However, you can still run a SQL script at the beginning or/and at the end of the deployment. For example, this can be used to insert or update rows in the tables at the end of the deployment.
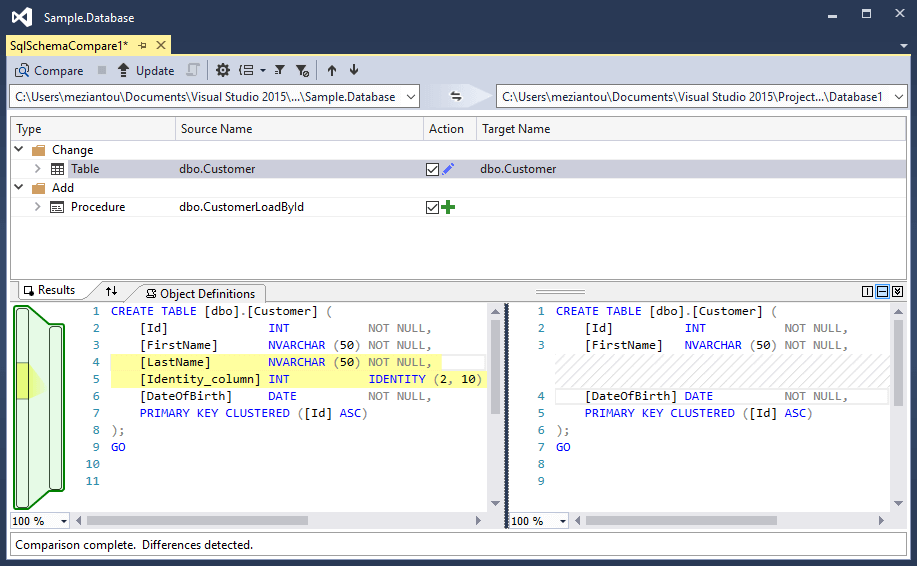
#Schema comparison
It is possible to compare the project content with an existing database, a dacpac file, or another SQL Server project. Once the comparison is done, you can update the target database or project. It is therefore possible to update the SQL Server project from an existing database.
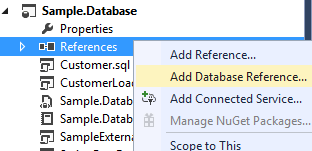
#Dependency management
SQL Server allows the use of Linked Server to execute a query across multiple databases.

The project is not aware of the ExternalDatabase database and therefore cannot resolve the name. As for a C# project, you can add a reference to the database. This reference can be of 3 types:
- Another SQL Server project
- A dacpac file
- An existing database
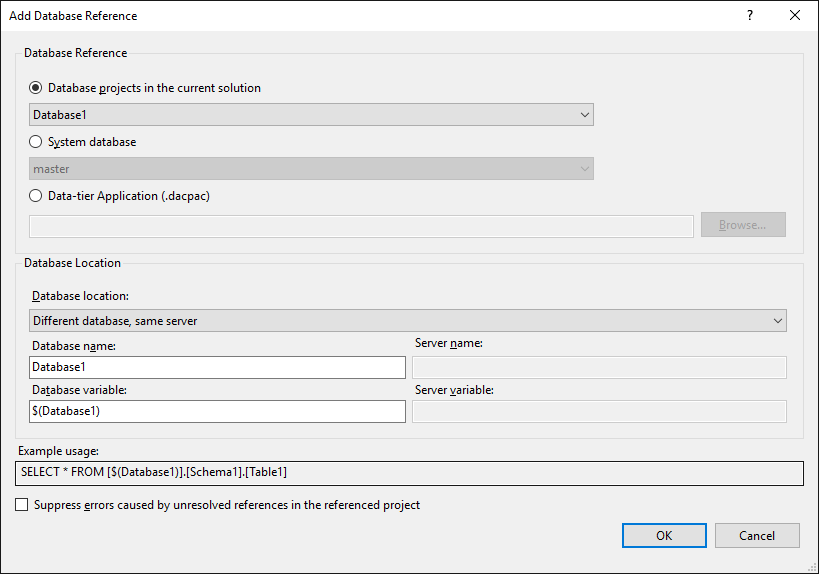
As indicated in the usage example, replace ExternalDatabase.dbo ... with the name of the variable created when adding the reference:
SQL
SELECT * FROM [$(ExternalDatabase)].dbo.Customer
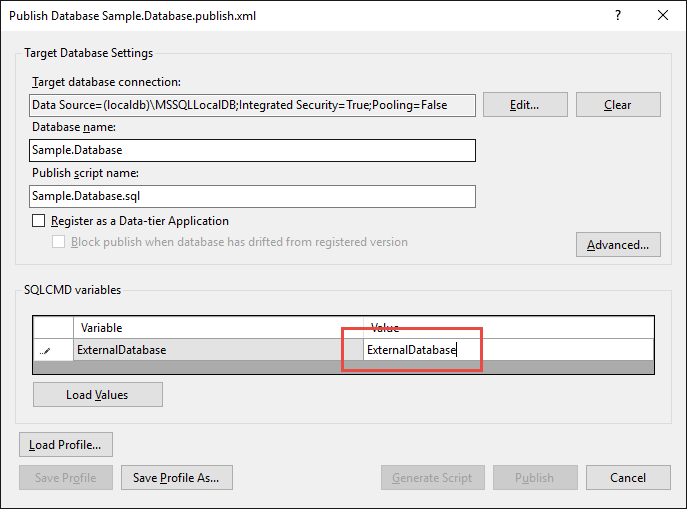
When publishing the database, it is possible to modify the value of this variable. This makes it possible to manage the case where the name of the external base differs between the development machine and the production.
#Conclusion
SQL Server Database projects simplify the creation of databases. It is fully integrated into the IDE and the source control, and allows the database to be deployed and updated to the desired SQL Server environment. Features such as refactoring are very valuable. In short a lot of good things when you want to create a database with SQL Server 😃
Do you have a question or a suggestion about this post? Contact me!