When you have a performance issue on a specific SQL query, the problem often, but not always, comes from the lack of indexes. An index as the name implies indexes the data of one or more columns. This makes it possible to search for data quickly and thus to accelerate the filters (WHERE), the joins (JOIN) and the groupings (GROUP BY). Consider the following query:
SQL
SELECT User_Email FROM [User] WHERE User_Email LIKE 'meziantou%'
Without index you have to go through the entire table to filter the lines as visible on this the execution plan:
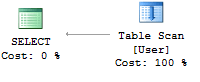
Let's create an index on the Email column:
SQL
CREATE INDEX UserEmail ON [user] (User_Email)
SQL Server can use this one to filter rows. The table scan is replaced with an index seek:

The problem you are facing is which indexes to create. Creating all possible indexes is not a viable solution because an index takes up space on the disk, and may reduce the performance of INSERT, UPDATE, or DELETE commands… On the other hand, creating no index is not satisfactory either. As often, you end up with the storage vs. performance dilemma.
The goal is to identify the requests for which the gain is real. For that you can use some metrics such as the execution time of the query, the number of executions, or the potential gain.
SQL Server does some of the work for you. For each query, SQL Server calculates an execution plan (list of steps to execute the query). During this computation, SQL Server stores the list of indexes that could have been used if they existed. To know the list of indexes to create one can simply ask SQL Server for this list.
SQL
SELECT
'CREATE INDEX [missing_index] ON ' + mid.statement
+ '('
+ ISNULL(mid.equality_columns, '')
+ CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ', ' ELSE '' END
+ ISNULL(mid.inequality_columns, '')
+ ')'
+ ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement,
migs.*, mid.database_id, mid.[object_id]
FROM sys.dm_db_missing_index_groups mig
INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle

Some information about the query:
equality_columns: list of columns used with the equality operator (=) in the query, for example, SELECT * FROM Demo WHERE Id = 42inequality_columns: list of used columns with the equality operator (<>, >, <, >=, <=) in the query, for example, SELECT * FROM Demo WHERE Id > 42- sys.dm_db_missing_index_groups: list of missing indexes
- sys.dm_db_missing_index_details: index details such as index column list
- sys.dm_db_missing_index_group_stats: allows to have indications on the relevance of the index
This view, although practical, has some limitations:
- Should the index be clustered or not?
- In the case of a multi-column index, what is the order of the columns of the optimal index? (the index (a,b) is not identical to the index (b,a))
- Which index will bring the most gains? The view still provides some metrics to help us:
avg_total_user_cost, avg_user_impact, user_seeks, user_scans
Do not forget you can use Database Engine Tuning Advisor for specific tips on optimizing a query. And do not forget to check the use of your indexes (sys.dm_db_index_operational_stats, sys.dm_db_index_usage_stats).
Do you have a question or a suggestion about this post? Contact me!