Some websites allow users to include HTML when they post comments. This may look like:
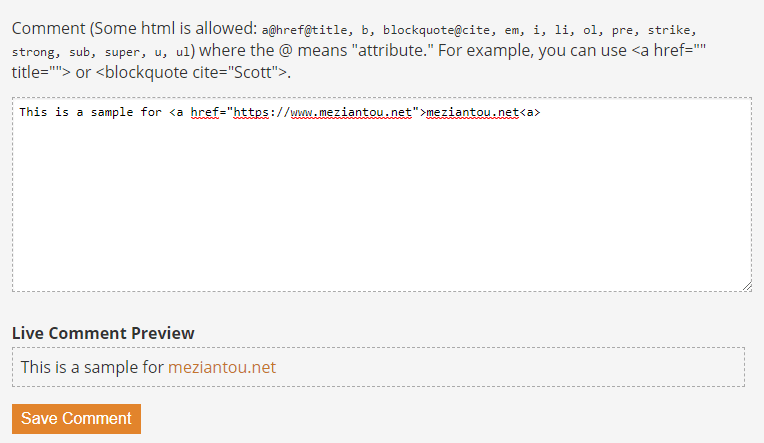 Add comment section on Scott Hanselman's blog
Add comment section on Scott Hanselman's blog
The website must remove all elements and attributes that are not allowed to avoid injection problems. In this post, we'll see how to use AngleSharp to parse the HTML snippet and remove dangerous attributes and elements.
AngleSharp is a .NET library that gives you the ability to parse angle bracket based hyper-texts like HTML, SVG, and MathML. The included parser is built upon the official W3C specification. This produces a perfectly portable HTML5 DOM representation of the given source code and ensures compatibility with results in evergreen browsers.
https://github.com/AngleSharp/AngleSharp
First, you need to install AngleSharp by including the following line in the csproj (NuGet package) or by using the package manager.
csproj (MSBuild project file)
<PackageReference Include="AngleSharp" Version="0.13.0" />
Then, you can parse an html fragment using the following code:
C#
private static IElement ParseHtmlFragment(string content)
{
var uniqueId = Guid.NewGuid().ToString("N");
var parser = new HtmlParser();
var document = parser.ParseDocument($"<div id='{uniqueId}'>{content}</div>");
var element = document.GetElementById(uniqueId);
Debug.Assert(element != null);
return element;
}
Then, you can traverse the content of the html element and remove what you don't want:
C#
public sealed class HtmlSanitizer
{
// Inspired from https://github.com/angular/angular/blob/4d36b2f6e9a1a7673b3f233752895c96ca7dba1e/packages/core/src/sanitization/html_sanitizer.ts
private const string VoidElements = "area,br,col,hr,img,wbr";
private const string OptionalEndTagBlockElements = "colgroup,dd,dt,li,p,tbody,td,tfoot,th,thead,tr";
private const string OptionalEndTagInlineElements = "rp,rt";
private const string OptionalEndTagElements = OptionalEndTagInlineElements + "," + OptionalEndTagBlockElements;
private const string BlockElements = OptionalEndTagBlockElements + ",address,article,aside,blockquote,caption,center,del,dir,div,dl,figure,figcaption,footer,h1,h2,h3,h4,h5,h6,header,hgroup,hr,ins,map,menu,nav,ol,pre,section,table,ul";
private const string InlineElements = OptionalEndTagInlineElements + ",a,abbr,acronym,b,bdi,bdo,big,br,cite,code,del,dfn,em,font,i,img,ins,kbd,label,map,mark,q,ruby,rp,rt,s,samp,small,span,strike,strong,sub,sup,time,tt,u,var";
private const string DefaulValidElements = VoidElements + "," + BlockElements + "," + InlineElements + "," + OptionalEndTagElements;
private const string DefaulUriAttrs = "background,cite,href,longdesc,src,xlink:href";
private const string DefaulSrcsetAttrs = "srcset";
private const string DefaultHtmlAttrs = "abbr,align,alt,axis,bgcolor,border,cellpadding,cellspacing,class,clear,color,cols,colspan,compact,coords,dir,face,headers,height,hreflang,hspace,ismap,lang,language,nohref,nowrap,rel,rev,rows,rowspan,rules,scope,scrolling,shape,size,span,start,summary,tabindex,target,title,type,valign,value,vspace,width";
private const string DefaulValidAttrs = DefaulUriAttrs + "," + DefaulSrcsetAttrs + "," + DefaultHtmlAttrs;
public ISet<string> ValidElements { get; } = SplitToHashSet(DefaulValidElements);
public ISet<string> ValidAttributes { get; } = SplitToHashSet(DefaulValidAttrs);
public string SanitizeHtmlFragment(string html)
{
var element = ParseHtmlFragment(html);
for (var i = element.ChildNodes.Length - 1; i >= 0; i--)
{
Sanitize(element.ChildNodes[i]);
}
return element.InnerHtml;
}
private void Sanitize(INode node)
{
if (node is IElement htmlElement)
{
if (!IsValidElement(htmlElement.TagName))
{
htmlElement.Remove();
return;
}
for (var i = htmlElement.Attributes.Length - 1; i >= 0; i--)
{
var attribute = htmlElement.Attributes[i];
if (!IsValidAttribute(attribute.Name))
{
htmlElement.RemoveAttribute(attribute.NamespaceUri, attribute.Name);
}
}
}
for (var i = node.ChildNodes.Length - 1; i >= 0; i--)
{
Sanitize(node.ChildNodes[i]);
}
}
private bool IsValidElement(string tagName)
{
return ValidElements.Contains(tagName);
}
private bool IsValidAttribute(string attributeName)
{
return ValidAttributes.Contains(attributeName);
}
private static HashSet<string> SplitToHashSet(string text)
{
return text.Split(',').ToHashSet(System.StringComparer.OrdinalIgnoreCase)
}
}
The last step is to sanitize the URI attributes. For instance, you don't want a user to enter <a href="javascript:alert('demo')">. So, you need to sanitize the URIs to avoid dangerous html.
C#
public static class UrlSanitizer
{
// https://github.com/angular/angular/blob/4d36b2f6e9a1a7673b3f233752895c96ca7dba1e/packages/core/src/sanitization/url_sanitizer.ts
private static readonly Regex s_safeUrlRegex = new Regex("^(?:(?:https?|mailto|ftp|tel|file):|[^&:/?#]*(?:[/?#]|$))", RegexOptions.IgnoreCase | RegexOptions.Compiled, TimeSpan.FromSeconds(1));
private static readonly Regex s_dataUrlPattern = new Regex("^data:(?:image/(?:bmp|gif|jpeg|jpg|png|tiff|webp)|video/(?:mpeg|mp4|ogg|webm)|audio/(?:mp3|oga|ogg|opus));base64,[a-z0-9+/]+=*$", RegexOptions.IgnoreCase | RegexOptions.Compiled, TimeSpan.FromSeconds(1));
private static readonly char[] s_whitespaces = new[] { ' ', '\t', '\r', '\n', '\f' };
public static bool IsSafeUrl(string url)
{
return s_safeUrlRegex.IsMatch(url) || s_dataUrlPattern.IsMatch(url);
}
public static bool IsSafeSrcset(string url)
{
return url.Split(',').All(value => IsSafeUrl(GetUrlPart(value)));
static string GetUrlPart(string value)
{
value = value.Trim(s_whitespaces);
var separator = value.IndexOfAny(s_whitespaces);
if (separator < 0)
return value;
return value.Substring(0, separator);
}
}
}
Finally, you can improve the html sanitizer to handle URIs:
C#
public sealed class HtmlSanitizer
{
// ...
public ISet<string> UriAttributes { get; } = SplitToHashSet(DefaulUriAttrs);
public ISet<string> SrcsetAttributes { get; } = SplitToHashSet(DefaulSrcsetAttrs);
// ...
private void Sanitize(INode node)
{
if (node is IElement htmlElement)
{
if (!IsValidNode(htmlElement.TagName))
{
htmlElement.Remove();
return;
}
for (var i = htmlElement.Attributes.Length - 1; i >= 0; i--)
{
var attribute = htmlElement.Attributes[i];
if (!IsValidAttribute(attribute.Name))
{
htmlElement.RemoveAttribute(attribute.NamespaceUri, attribute.Name);
}
// 👇 Ensure URIs are not dangerous
else if (UriAttributes.Contains(attribute.Name))
{
if (!UrlSanitizer.IsSafeUrl(attribute.Value))
{
attribute.Value = "";
}
}
else if (SrcsetAttributes.Contains(attribute.Name))
{
if (!UrlSanitizer.IsSafeSrcset(attribute.Value))
{
attribute.Value = "";
}
}
}
}
for (var i = node.ChildNodes.Length - 1; i >= 0; i--)
{
Sanitize(node.ChildNodes[i]);
}
}
}
The next step would be to sanitize the content of the style element and attribute. I didn't need it, so I haven't implemented it. If you want to implement it, AngleSharp contains a CSS parser that may help.
Do you have a question or a suggestion about this post? Contact me!